An introduction to web service scaling
Designing a system that could serve millions of requests will always be a big challenge. Fortunately, there are multiple solutions to this problem. Depending on how large your system could be, you could utilize these solutions or combine them for a better result.
Disclaimer: I learned this knowledge from the book “System Design Interview: An Insider’s Guide“ by Alex Xu.
This post covers a tiny part of the book. Please read the book for more information.
1. Some basic concepts
1.1. What to scale?
A web service is a composite of multiple components. In the most straightforward system, they are:
- Database
- Server
- Client
When we talk about scaling up the web service, we focus on database and server only. We can do nothing from the client side since we cannot force the client to use a specific device to access the web service.
Depending on the nature of your system and/or where the bottleneck is, you could choose which component to scale up to serve more requests.
For example, if your system stores a vast amount of data and accesses them frequently, you may want to scale up the database. However, if your system is heavy on the calculation, then you may want to scale up the server. Of course, you can scale up both components. It is always the price/performance problem.
1.2. Scaling directions
There are 2 ways to scale a system:
- Scale-up: Adding more processing power (CPU, RAM, Storage)
- Scale-out: Adding more servers
You cannot add an unlimited amount of CPU power, RAM, or storage. Adding more server to a system also add new problems like data consistency, choosing the server, concurrency access, etc. They are challenging, but fear not, there are solutions.
2. Geting scaled
2.1. Database scaling
A database has 4 basic operations: CREATE-READ-UPDATE-DELETE. For each operation, there are specific ways to scale.
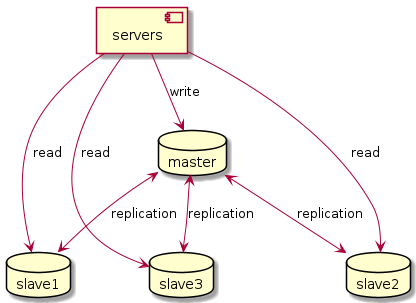
2.1.1. Database Replication
For example, when you need to read a lot but write sometimes, you can use Database Replication, with one master database and multiple slaves.
2.1.2. Database sharding
Sharding, or partitioning, is another approach to database scaling. You still use multiple databases, but different from replication, each database holds a portion of the data. A sharding strategy could be used to determine which data belong to which database.
For example, you can store all records with odd id to a database and even id to another.
However, this will introduce some new problems:
- What if all database is used up to their limit, and you need to add a new database?
- What if the data of a query is allocated to multiple databases?
- What if you need to remove a shard and copy its data to all other operational shards?
There are other clever ways to scale the database, suitable for very specific systems. The key is to split and conquer.
2.1.3. Use a different type of database technology
To SQL or NoSQL? Graph or table? Free or commercial? There are multiple databases technology out there. Based on the project’s business logic, the architect must choose the best database technology.
For example, you can store all kinds of data in MongoDB and read them with extremely high performance and low cost. However, MongoDB doesn’t have join operation, Transaction, or Trigger.
2.2. Server Scaling
The ultimate goal of scaling is to handle increasing traffic, or to reduce the response time of a single request. To do so, there are some solutions
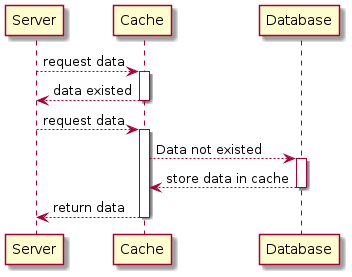
2.2.1. Cache
If the data will not change for a relatively long time, we can use cache to store that data. Whenever the data is needed, server read it directly from cache without calculation or take trip to database.
2.2.2. Stateless and multiple servers
Stateless mean the server does not store the state of the request. Every requests are treated the same. This is important, because the servers don’t save state of the request, we can easily add more identical servers to increase the performance.
However, to use multiple servers for a web service, we need a way to direct the request to the idle server. We call it the Load Balancer.
Load Balancer
How exactly load balancer balance the request between servers? By using some algorithm, the load balancer can evenly distribute the request.
For example: The round robin algorithm. All server sit on a circle. The load balancer distribute one request to a server, then distribute the next request to the next server on the circle.
2.2.3. Microservice Architecture
What if there is only one component get extremely high traffic? Is there anyway to scale components of the system separately?
Microservice is an architecture that split the components of the server into smaller, stand-alone services. These services communicate with each other internally.
When using Microservice architecture, developers can develop each services at different pace. For example, authentication service will not change much, but feature service will change over time.
However, Microservice Architecture introduce some problems. If not used correctly, it could become a mess for the development.
An excellent post about these problems: Disasters I’ve seen in a microservices world
3. What about the client?
If we know for sure that our client is not some 1992 machine with limited CPU power and memory, then we can use the REST architecture.
In short, the rendering (displaying text and image, animation, etc) jobs could be handled by the client. By this way, the server is only care about serving the data requested by the client.
To increase the download speed of the client, we could use CDN (Content Delivery Network) to serve static resources like JavaScript library, images, videos and audios, as well as CSS libraries.
That’s it. See you in next post